
I am a first-year Ph.D. student in Computer Science at Iowa State University, supervised by Professor Yang Li. I earned my M.S. and B.Eng. in Computer Science from Zhejiang University, where I was advised by Professor Zhou Zhao. My research focuses on Multimodal Learning and Computer Vision.
📝 Publications

KiToke: Kernel-based Interval-aware Token Compression for Video Large Language Models.
Haifeng Huang, Yang Li
- KiToke is a training-free method that compresses video tokens by removing global redundancy while preserving temporal coherence for efficient Video LLM inference.
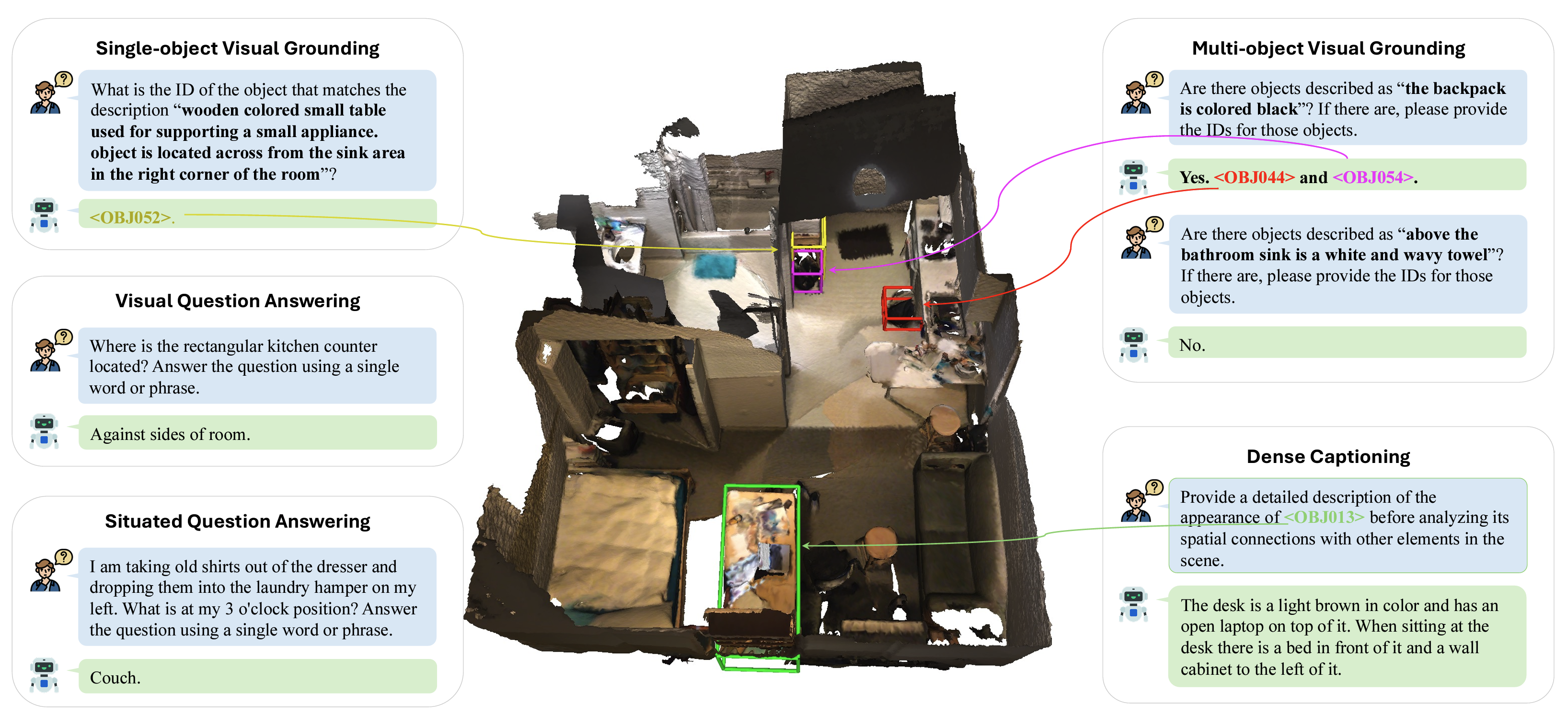
Chat-Scene: Bridging 3D Scene and Large Language Models with Object Identifiers.

Haifeng Huang, Yilun Chen, Zehan Wang, Rongjie Huang, Runsen Xu, Tai Wang, Luping Liu, Xize Cheng, Yang Zhao, Jiangmiao Pang, Zhou Zhao

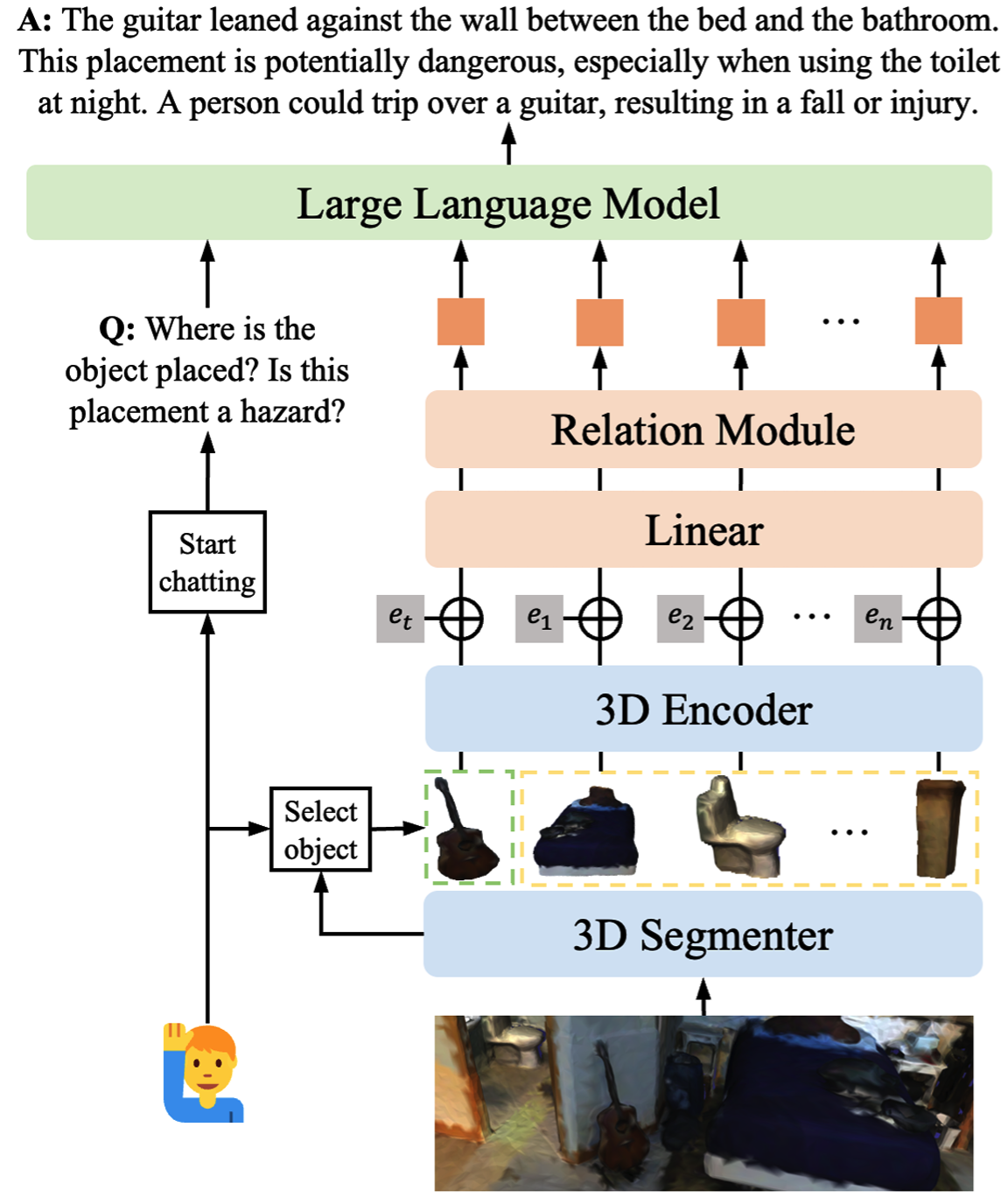
Grounded 3D-LLM with Referent Tokens.

Yilun Chen*, Shuai Yang*, Haifeng Huang*, Tai Wang, Ruiyuan Lyu, Runsen Xu, Dahua Lin, Jiangmiao Pang.
- Grounded 3D-LLM establishes a correspondence between 3D scenes and language phrases through referent tokens.
- Create a large-scale grounded scene caption dataset at phrase-level.
Chat-3D: Data-efficiently Tuning Large Language Model for Universal Dialogue of 3D Scenes.

Zehan Wang*, Haifeng Huang*, Yang Zhao, Ziang Zhang, Zhou Zhao.
- Chat-3D is one of the frist 3D LLMs.
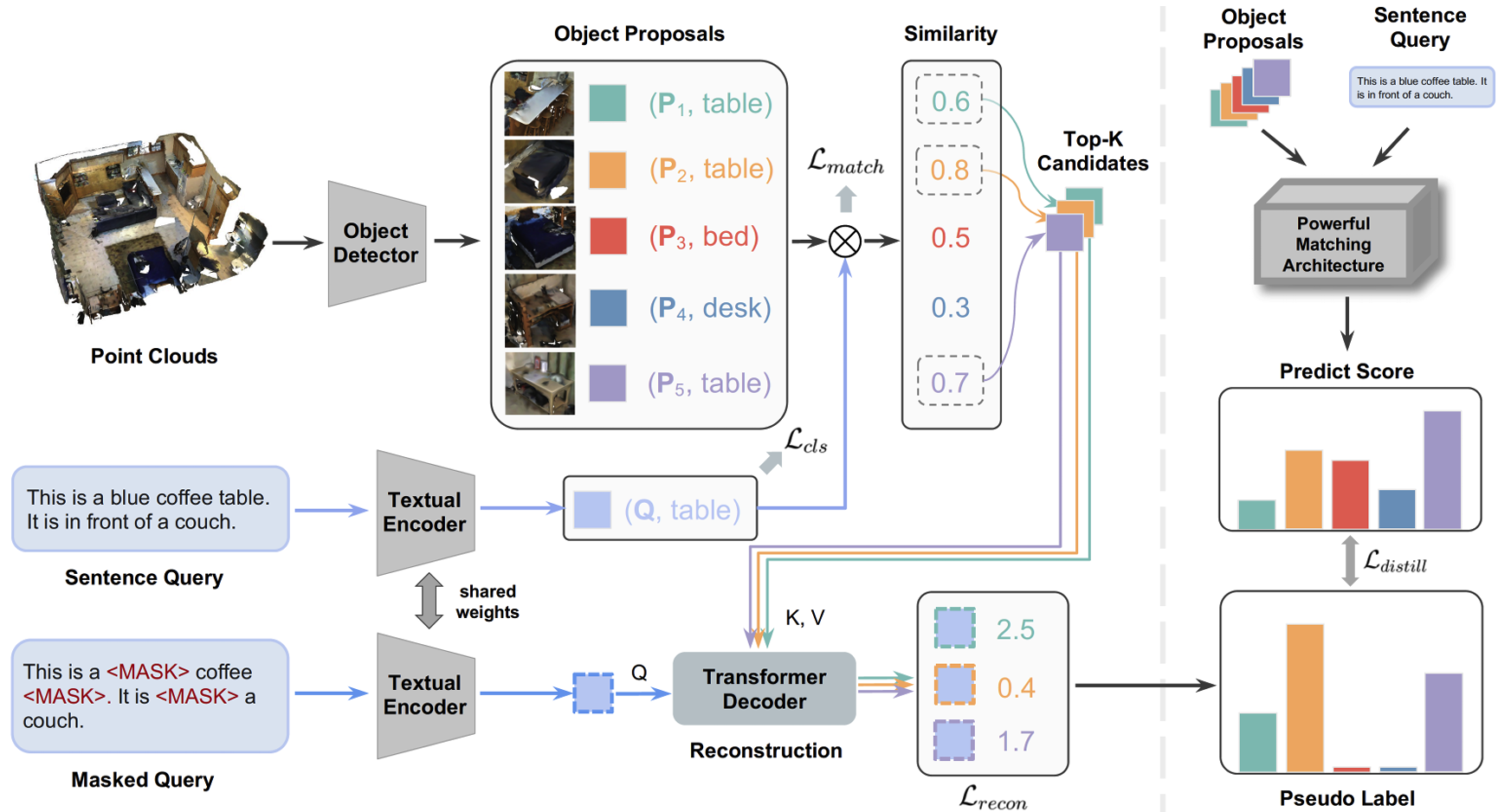
Distilling Coarse-to-Fine Semantic Matching Knowledge for Weakly Supervised 3D Visual Grounding.
Zehan Wang*, Haifeng Huang*, Yang Zhao, Linjun Li, Xize Cheng, Yichen Zhu, Aoxiong Yin, Zhou Zhao
- The first weakly-supervised 3D visual grounding method.
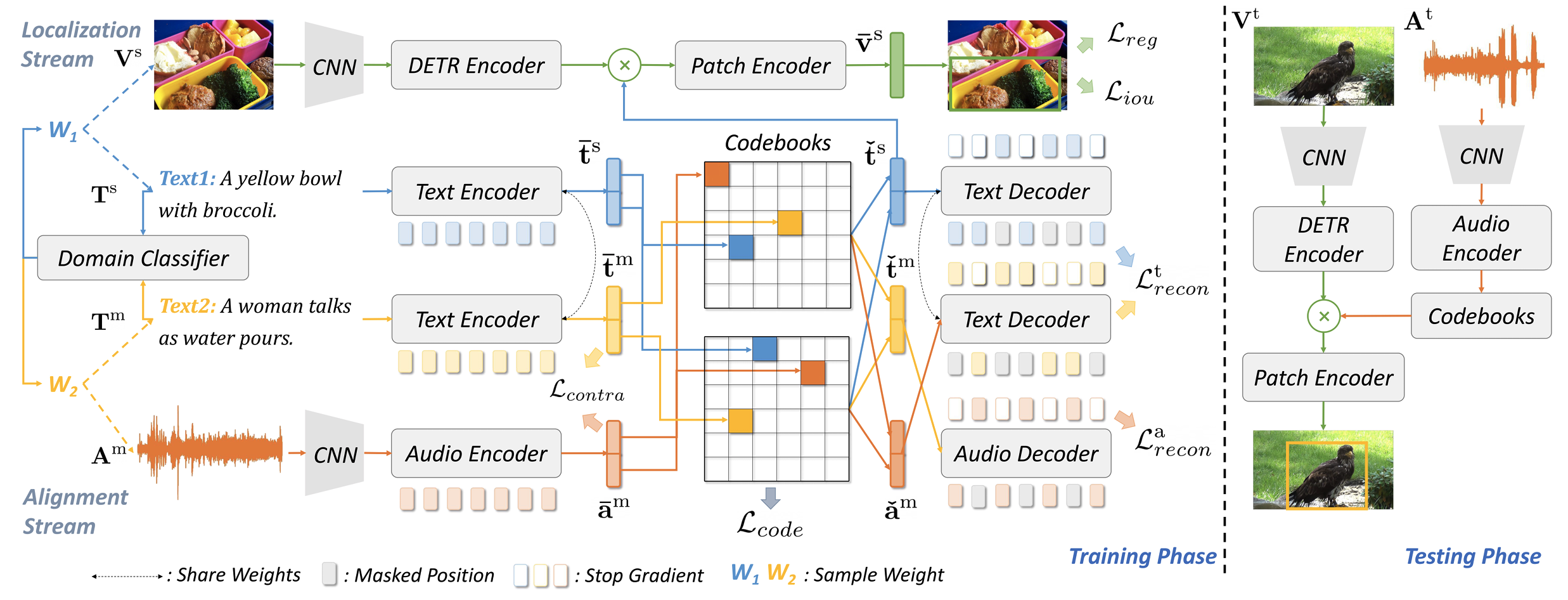
Towards Effective Multi-modal Interchanges in Zero-resource Sounding Object Localization.
Yang Zhao*, Chen Zhang*, Haifeng Huang*, Haoyuan Li, Zhou Zhao
- A method for sounding object localization without training on any prior data in this field.
📖 Education
- 2025.09 - Present, Ph.D. in Computer Science, Iowa State University.
- 2022.09 - 2025.04, M.S. in Computer Science, Zhejiang University.
- 2018.09 - 2022.06, B.Eng. in Computer Science, Zhejiang Univeristy.